Synthetic data generation
Objective
To explore data synthesis techniques for single tables, relational tables, and entire databases, that preserve the statistical properties and structural relationships of the original datasets while ensuring data privacy and protection. As a proof of concept (POC), we implement the synthesis process for a more complex scenario involving relational medical tables.
Background and importance of data synthesis
Data synthesis refers to the creation of artificial data that mimics the statistical properties of the real-world data. With the rise of machine learning, data synthesis techniques advanced with generative models like GANs and VAEs, enabling more realistic synthetic data.
The importance of data synthesis lays in aspects such as privacy protection, data availability, safe testing and development, cost efficiency, as it enables organizations to create realistic datasets without exposing sensitive information, facilitates the generation of data when the real data does not exist or access is limited, supports robust testing and development processes, and reduces costs associated with data acquisition and management.
Dataset overview
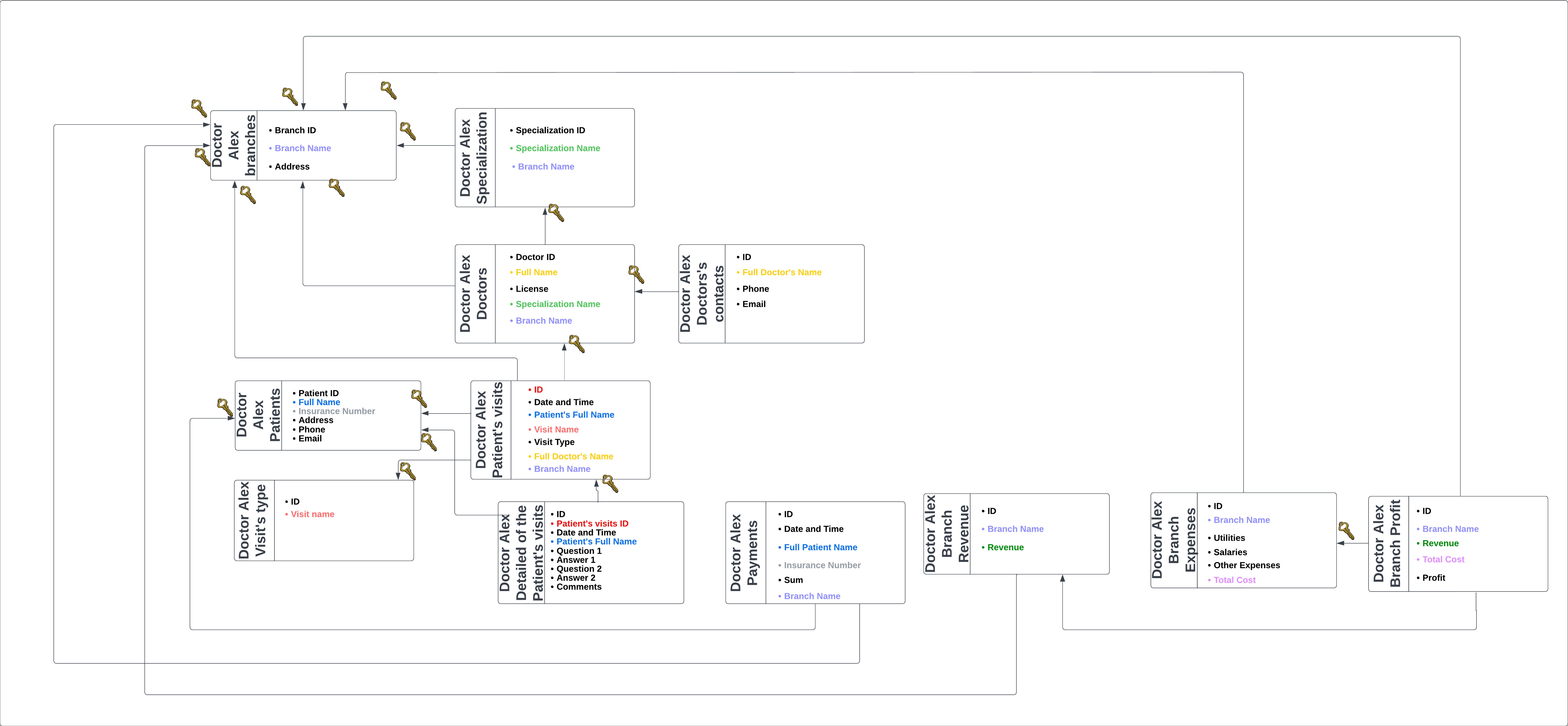
This research employed a comprehensive, interconnected medical dataset designed to simulate the complexity of real-world healthcare information systems. It’s important to note that while most publicly available datasets typically consist of single, unrelated tables, we chose to create our own interconnected set of tables for this research. This decision was made to more accurately represent the complexity of real-world data systems and to ensure a diverse range of data types within the tables, to provide a more challenging and realistic scenario for testing data synthesis techniques.
Our dataset comprises twelve related tables, each representing a critical component of a healthcare organization’s data structure. This intricate design allowed for a thorough evaluation of various data synthesis techniques, challenging their ability to preserve both statistical properties and complex relational structures.
The dataset incorporates a variety of data types, including:
- Integer for IDs and numeric identifiers
- String for names, addresses, and descriptive fields
- Float for financial figures
- Datetime for time-related fields
You can view our dataset here.
Additionally, we have created a simplified version of this dataset tailored for a MySQL database. This version is streamlined, utilizing IDs as primary and foreign keys to maintain relational integrity. This simplified dataset is specifically designed for use with the Gretel workflow, enabling more efficient testing and data generation within a relational database context.
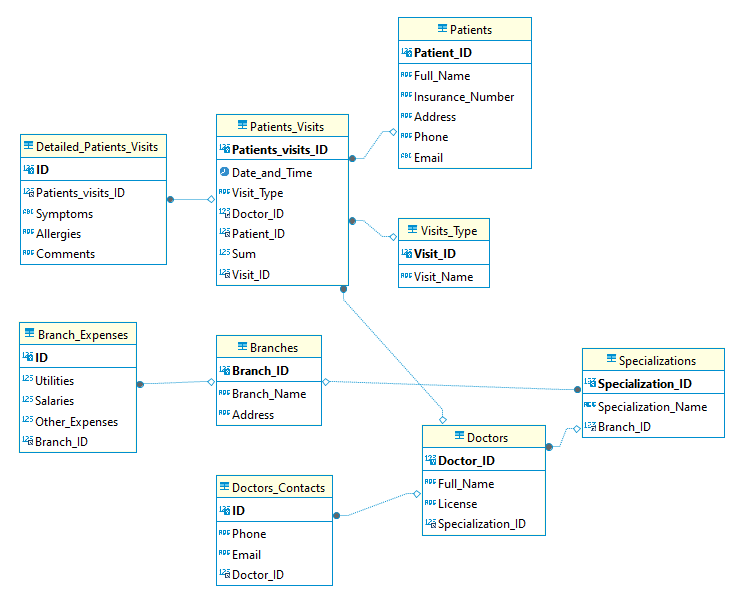
Techniques explored
In our research on data synthesis for complex, relational datasets, we selected four distinct approaches, each offering unique features and capabilities. These techniques were chosen to represent a spectrum of methods, from custom-built solutions to ready-made platforms, allowing us to comprehensively evaluate the state of the art in synthetic data generation.
1. Tabular Variational Autoencoder (Tab-VAE)
Theory and Implementation:
Our exploration of data synthesis began with the development of a Self-made Variational Autoencoder (VAE). This custom-built model offered an in-depth understanding of data generation complexities, particularly for relational datasets. While VAEs present a strong theoretical foundation for synthetic data generation, they face challenges such as overpruning and posterior collapse, especially when working with high-dimensional latent spaces. This issue is exacerbated in tabular data, where categorical one-hot encoding expands feature dimensions significantly. To address these challenges, we discovered Tab-VAE, a novel VAE-based approach designed specifically for tabular data. Tab-VAE incorporates a sampling technique for categorical variables at inference, improving its capacity to generate realistic synthetic tabular data.
Advantages and Limitations:
The Tab-VAE model presents several advantages over traditional VAE approaches and GAN-based generators. It effectively mitigates problems like overpruning and posterior collapse by introducing a robust sampling method for categorical features, thus enhancing the quality of synthetic data generation. This method not only addresses the dimensionality issues inherent in tabular data but also delivers better performance compared to existing models. Additionally, Tab-VAE offers a more stable and computationally efficient alternative to GAN-based models, making it a practical choice for generating synthetic tabular data. However, limitations include its reliance on the sampling technique, which might not be universally applicable across all types of tabular data and could require further refinement to handle more complex datasets.
2. Gretel.ai
We implemented a synthetic data generation pipeline using Gretel with an AWS-hosted MySQL database. This approach involved connecting to a remote MySQL database on AWS, configuring Gretel for data extraction and synthetic data generation, and managing the entire workflow through Gretel’s API. This showcases how to leverage cloud-based databases in conjunction with synthetic data generation tools.
Implementation
The implementation of the Gretel synthetic data generation involved several key steps:
Data Extraction from AWS MySQL Database
We connected to a MySQL database hosted on AWS to extract data from various tables. This process involved:
-
Remote Database Connection: Establishing a connection to the AWS-hosted MySQL database to access the data.
-
Data Extraction: Extracting data from each table and storing it in a structured format for further processing.
Gretel Configuration
We set up Gretel to manage data connections and workflows as follows:
-
Session Initialization: Configured a Gretel session using the API key.
-
Project Creation: Created or retrieved a unique project in Gretel for the synthetic data generation process.
-
AWS MySQL Connection: Registered the AWS MySQL connection in Gretel to facilitate data integration.
Workflow Configuration and Execution
-
We defined and executed a Gretel workflow to generate synthetic data:
-
Workflow Design: Configured the workflow to extract data from the AWS MySQL database and train a synthetic data model using Gretel’s tools.
-
Workflow Execution: Ran the workflow and monitored its progress through Gretel’s logging and reporting features.
Advantages
-
Cloud Integration: The pipeline integrates seamlessly with a cloud-based MySQL database, offering scalability and flexibility.
-
Automation and Monitoring: The automated workflow handles data extraction, model training, and progress monitoring, streamlining the process.
-
Customizable Models: Gretel provides the flexibility to select and configure different models for data synthesis, enhancing the quality of synthetic data. Models included: Gretel ACTGAN - Adversarial model for tabular, structured numerical, high column count data. Gretel Tabular DP - Graph-based model for tabular data with differential privacy. Gretel GPT - Generative pre-trained transformer for natural language text. Gretel DGAN - Adversarial model for time-series data.
Limitations
-
Remote Connection Management: Configuring and managing remote database connections requires careful attention to network and security settings.
-
Processing Time: Generating large volumes of synthetic data can be time-consuming due to the model’s computational requirements.
-
Data Duplication: Ensuring the uniqueness of generated data can be challenging, and additional validation may be necessary.
Results evaluation
General evaluation
- Relational Report - A comprehensive overview of the relational structure and integrity of the dataset.
Cross-table evaluation
- Synthetics Cross Table Evaluation: Branch Expenses
- Synthetics Cross Table Evaluation: Doctors
- Synthetics Cross Table Evaluation: Doctors Contacts
- Synthetics Cross Table Evaluation: Patients Visits
- Synthetics Cross Table Evaluation: Specializations
Single-table evaluation
- Synthetics Individual Evaluation: Branches
- Synthetics Individual Evaluation: Branch Expenses
- Synthetics Individual Evaluation: Detailed Patients Visits
- Synthetics Individual Evaluation: Doctors
- Synthetics Individual Evaluation: Doctors Contacts
- Synthetics Individual Evaluation: Patients
- Synthetics Individual Evaluation: Patients Visits
- Synthetics Individual Evaluation: Specializations
- Synthetics Individual Evaluation: Visits Type
3. Langchain synthetic data generation pipeline
We explored the Langchain data synthesis, another ready-made pipeline that necessitates significant configuration. This approach leverages the power of large language models for data synthesis, presenting a unique perspective on how AI can be utilized in generating diverse and creative synthetic datasets.
Implementation
The implementation of the Langchain synthetic data generation pipeline involved several key steps:
Pydantic Class Creation:
- For each table in our medical dataset, we created corresponding Pydantic classes.
- These classes defined the structure and data types of each field in the tables.
Algorithmic Configuration of Extra Prompts: To improve the quality and consistency of the generated synthetic data, we dynamically configured the extra prompts passed to the language model based on the relationships between tables:
- If a field referenced data from another table (e.g., Branch_Name, Specialization_Name, Full_Name), we loaded the existing synthetic data for that related table and passed the unique values as part of the extra prompt. This ensured referential integrity.
- We also included general guidelines in the extra prompts, such as avoiding data duplication, maintaining unique identifiers, and generating realistic and consistent data.
By dynamically tailoring the extra prompts based on the table relationships and data requirements, we aimed to improve the quality, consistency, and relational integrity of the generated synthetic data.
Example-based Generation:
- For each table, we selected a subset of real data (e.g., the first 10 rows) and transformed them into example strings that showcased the expected structure and content.
Pipeline Configuration:
- We set up the Langchain pipeline, specifying the language model to use and the desired output format.
Advantages:
- Langchain’s use of language models allows for the generation of highly diverse and creative synthetic data.
- The model can generate data with a good understanding of context and relationships between fields.
- Can handle various data types and structures, making it versatile for different kinds of datasets.
Limitations:
- The biggest challenge was accurately representing relationships between tables. For each table, we needed to provide extensive descriptions and examples of already generated synthetic data from related tables. Without this, the model couldn’t maintain relational integrity.
- We observed a high rate of data duplication in the generated output, which reduced the representativeness of the synthetic dataset.
- Sometimes, the generated data didn’t perfectly align with the defined schemas, requiring additional validation and cleaning steps.
- Generating large volumes of data was time-consuming due to the model’s processing requirements.
Dublication examples in the “Contacts” and “Doctors” tables

4. SDV library HMA Synthesizer
Synthetic Data Vault (SDV) is a Python library for generating synthetic data that mimics the structure and properties of real-world datasets. It provides various synthesizers for different data types and structures, including single-table, multi-table, and time series data.
Hierarchical Multi-Agent (HMA) Synthesizer
The Hierarchical Multi-Agent (HMA) Synthesizer is a ready-made pipeline in the SDV library specifically designed for generating synthetic data for single table and multi-table datasets with complex relationships. It uses a hierarchical approach to model the dependencies between tables and generate consistent synthetic data across the entire dataset.
Multi-Table data details
To use the HMA Synthesizer, you need to provide:
- A dictionary of DataFrames representing the tables in your dataset.
- A MultiTableMetadata object that describes the structure, data types, and relationships between the tables.
The MultiTableMetadata can be automatically detected from the input DataFrames using the detect_from_dataframes() method, but it may require manual adjustments to accurately capture the relationships and data types.
Advantages
- Handles complex multi-table datasets with various types of relationships (one-to-one, one-to-many, many-to-many).
- Generates synthetic data that preserves the structure and statistical properties of the original dataset.
Limitations
- Requires all tables and columns to be specified in a strict hierarchical format. Currently, the HMA synthesizer cannot produce good data for datasets with more than 5 tables or a depth exceeding 1.
- The MultiTableMetadata may require manual adjustments to accurately represent the relationships between tables, which can be time-consuming for complex datasets.
- The synthesizer’s performance may degrade with increasing dataset size and complexity.
- The generated synthetic data consists of the same values present in the original tables, albeit rearranged and combined differently. While this approach ensures unique combinations in the synthesized data, it may lack the diversity and realism that comes with generating entirely new values, as seen in language models like GPT, which can create novel and contextually appropriate content.
Costs
Langchain Synthetic Data Generation Pipeline Pricing
Generating 50 rows of data with 3 columns using GPT-4o model costs approximately $0.19. This translates to a cost of about $0.00127 per cell, where extra prompting consumes 30 tokens.
Gretel.ai Pricing
Gretel.ai offers a flexible pricing model that starts with a free tier, providing 15 free credits per month. These credits are sufficient for generating over 100,000 synthetic records using Gretel Workflows, transforming 2 million records, or detecting PII in over 2 million records. Additional credits cost $2.00 each.
For more extensive usage, Gretel offers a Team plan at $295 per month, with each additional credit priced at $2.20. This plan includes up to 10 concurrent jobs, a 99.5% API availability SLA, and support options including custom SSO.
Enterprise plans are available for organizations needing customized scaling, 24/7 support, and dedicated success engineering. Pricing for these plans is tailored to specific enterprise needs.
Conclusion
We explored various data synthesis techniques for generating synthetic data from complex, relational datasets. We investigated four distinct approaches: a custom-built Tabular Variational Autoencoder (Tab-VAE), the Gretel.ai platform, the Langchain synthetic data generation pipeline, and the Synthetic Data Vault (SDV) library with its Hierarchical Multi-Agent (HMA) Synthesizer.
Our findings reveal several limitations across the different techniques. Non-LLM methods, often struggle with generating truly diverse synthetic data. The synthesized data tends to consist of the same values present in the original tables, albeit rearranged and combined differently. This lack of diversity may limit the realism and utility of the synthetic data for certain applications.
Moreover, maintaining the connections and relationships between tables remains a challenge across all techniques. The generated synthetic data may not always preserve the relational integrity of the original dataset, which can hinder its usefulness in scenarios that rely on accurate representations of these connections.
LLM-based techniques like the Langchain pipeline face an additional challenge: the occurrence of repeated rows in the generated data and connections are not always maintained.
You can also view our code here.