NLP-to-SQL
Objective
Develop an NLP-to-SQL system with a Swagger interface where users input natural language queries, and the system returns the results and the corresponding SQL query using GPT-4о.
Key Technologies
FastAPIfor the web framework and Swagger UItext-embedding-ada-002for embedding the database schemaPostgreSQLwithpgvectorextension for storing both textual schema and vector embeddings, and for vector similarity searchesGPT-4оfor natural language toSQLconversion
System Architecture
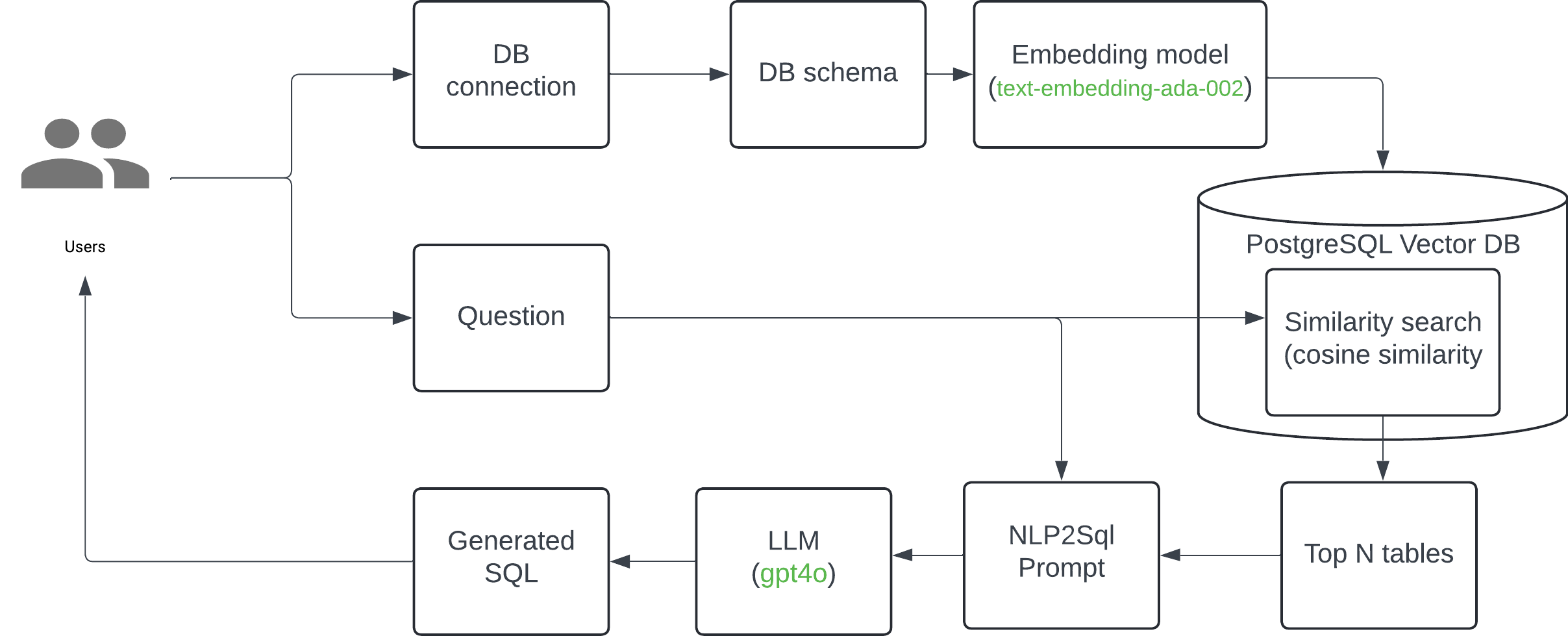
User Interface
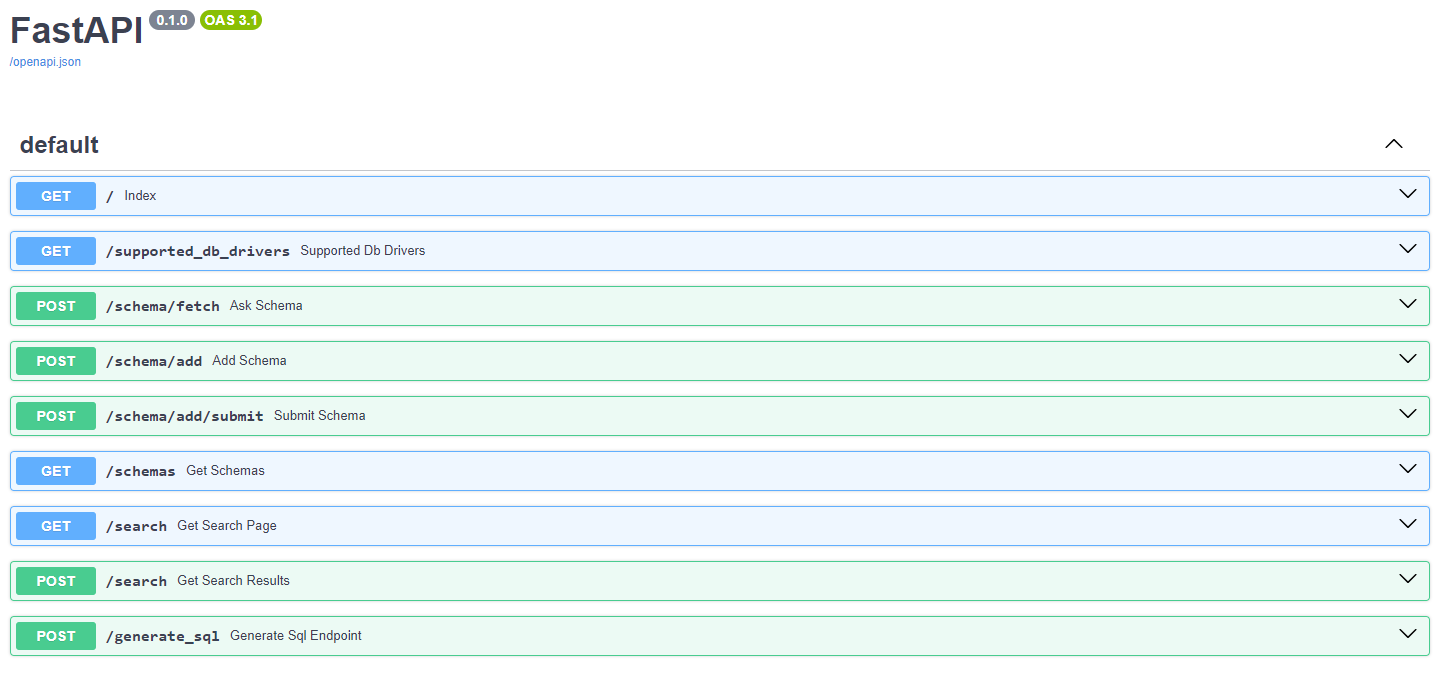
- The system uses
FastAPI, providing a Swagger UI for API documentation and user interaction. - API endpoints include operations for fetching schemas, adding schemas, searching, and generating
SQL.
Data Flow
- DB Connection and Schema Processing
- The system connects to a database to fetch the DB schema.
- When adding a schema to
PostgreSQL:- The textual schema is stored in the database.
- The schema is processed using the
text-embedding-ada-002model. - The resulting embeddings are also stored in the
PostgreSQLdatabase. - This process utilizes the
pgvectorextension inPostgreSQLfor efficient storage and retrieval of vector embeddings.
- User Query Processing
- Users input questions through the API.
- The question is used to perform a similarity search in the
PostgreSQLdatabase using the stored embeddings. - This search returns the top N relevant tables.
- NLP-to-SQL Conversion
- The user’s question and the top N tables are used to modify an NLP-to-SQL prompt. We based this prompt on the implementation described in Pinterest’s text-to-SQL approach.
- This prompt is sent to an LLM (
GPT-4о). - The LLM generates the SQL query based on the prompt.
- Results
- The generated SQL in JSON format is returned to the user.
- This SQL would then be executed against the actual database to retrieve results.

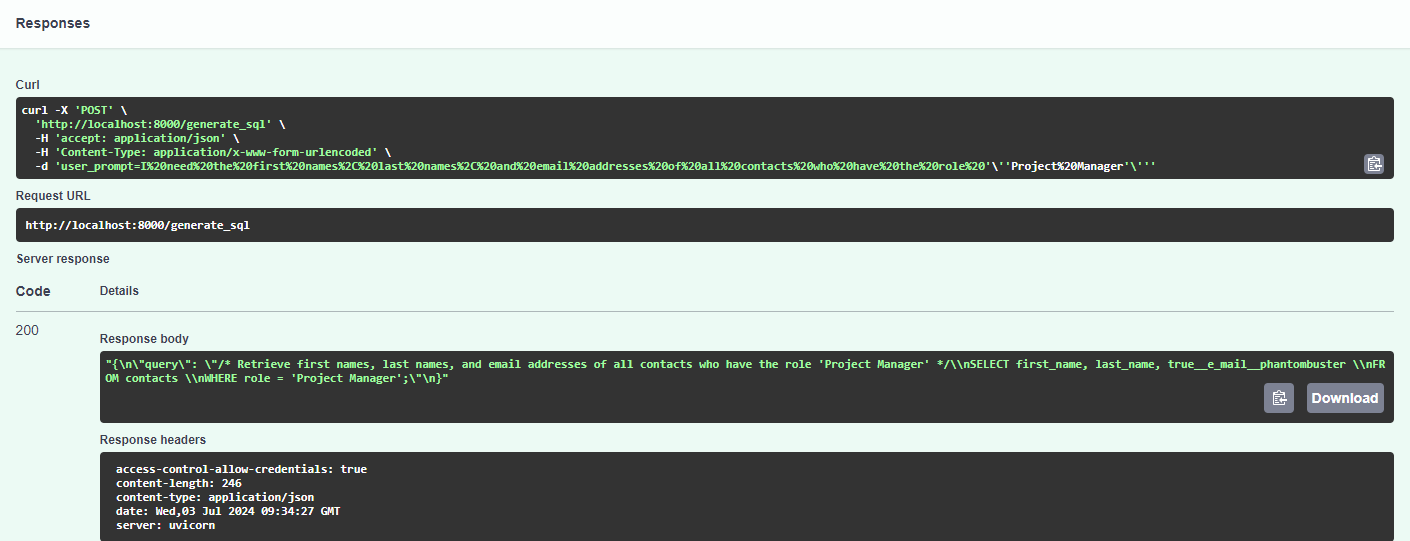
Result example:
Prompt: ‘I need the first names, last names, and email addresses of all contacts who have the role Project Manager’.
Result:
{
"query": "/* Retrieve first names, last names, and email addresses of all contacts who have the role Project Manager */\nSELECT first_name, last_name, true__e_mail__phantombuster \nFROM contacts \nWHERE role = 'Project Manager';"
}
Testing Notes
1. Query for Contacts and Companies
Expected Request:
SELECT contacts.first_name AS firts_name,
contacts.ornagization_name AS organization_name,
companies.DOMAIN AS DOMAIN
FROM contacts
JOIN companies ON contacts.campaign=companies.campaigns__pls_keep_the_original_one___first_;
Request from /generate_sql:
SELECT c.first_name,
c.ornagization_name AS organization_name,
com.domain
FROM contacts C
JOIN companies com ON c.ornagization_name = com.linkedin_organization_name
ORDER BY first_name;
- The presence of similar names can cause confusion (example:
ornagization_nameandlinkedin_organization_name).
2. Query for Last Contact Date
Expected Request:
SELECT _last_contact_date__phantombuster_inbox_scraper_ AS last_contact_date
FROM contacts
WHERE _last_contact_date__phantombuster_inbox_scraper_ BETWEEN '1/1/2020' AND '1/31/2024'
ORDER BY _last_contact_date__phantombuster_inbox_scraper_ DESC;
Request from /generate_sql:
SELECT _last_contact_date__phantombuster_inbox_scraper_
FROM contacts
WHERE _last_contact_date__phantombuster_inbox_scraper_ BETWEEN '2020-01-01' AND '2024-12-31'
ORDER BY _last_contact_date__phantombuster_inbox_scraper_ DESC;
- It is necessary to take into account the type of data and their format and, if necessary, change the request.
3. Query for Top 10 Companies by LinkedIn Followers
Prompt1 (long): This query retrieves the top 10 companies with the highest number of LinkedIn page followers. It first selects the company names and their corresponding LinkedIn page followers from the Companies table, ordering them in descending order based on the number of followers. Then, it limits the result to the top 10 companies. Finally, the outer query selects these top 10 companies, listing their names and the number of LinkedIn page followers.
1st Version of the Generated SQL:
SELECT linkedin_organization_name, linkedin_page_followers
FROM companies
ORDER BY CAST(linkedin_page_followers AS INTEGER) DESC -- it works if remove
LIMIT 10;
2nd Version of the Generated SQL:
SELECT linkedin_organization_name, linkedin_page_followers
FROM companies
ORDER BY linkedin_page_followers DESC
LIMIT 10;
3rd Version of the Generated SQL:
SELECT linkedin_organization_name, linkedin_page_followers
FROM (
SELECT linkedin_organization_name, linkedin_page_followers
FROM companies
ORDER BY CAST(linkedin_page_followers AS INTEGER) DESC -- it works if remove
LIMIT 10
);
Prompt2 (short): Finds the top 10 companies with the most LinkedIn followers by selecting and ordering them from the Companies table.
1st Version of the Generated SQL:
SELECT linkedin_organization_name, linkedin_page_followers
FROM companies
ORDER BY linkedin_page_followers DESC
LIMIT 10;
2nd Version of the Generated SQL:
SELECT linkedin_organization_name, linkedin_page_followers
FROM companies
ORDER BY CAST(linkedin_page_followers AS INTEGER) DESC -- it works if remove
LIMIT 10;
- It is necessary to take into account the values in tables and, if necessary, change the data and validate them.
Potential Enhancements
One of the key improvements to the current system would be to enhance its capability by not only generating SQL queries but also executing them against the actual database. This would enable the system to provide comprehensive results with not only the generated SQL query but also the query results. Additionally, developing a more user-friendly interface would significantly improve the overall user experience. This could include adding intuitive forms and visual tools that make interaction with the system easier and more efficient.
Challenges and Solutions
Initially, we tried to use tokenization for vector representation. However, this approach led to poor results due to padding issues. To overcome this, we switched to using the text-embedding-ada-002 model, which provided a more accurate representation of the database schema. This change significantly enhanced the system’s ability to comprehend and interact with the database, leading to more reliable and precise query results.
Conclusions
The development of the NLP-to-SQL system with a Swagger interface using GPT-4о and advanced embedding techniques has shown promising results. By addressing the challenges related to schema understanding and leveraging cutting-edge technologies, we have created a robust system that translates natural language queries into SQL queries effectively. Future enhancements will focus on executing the SQL queries to return actual query results, further improving the system’s practicality.
You also can clone our project and test it here: https://github.com/greenmorg/nlp-sql